



En ocasiones puede parecer confuso saber exactamente qué doble de test aplicar en cada momento. Cuando empezamos descubrimos la API de mock de PHPUnit y lo usamos para todo… pero los dobles de tests esconden una vertiente algo más organizativa, la cual, si no intentamos aplicar el doble de test adecuado, nos perdemos una parte importante de aprendizaje sobre nuestro código y la dirección que está tomando.
TODO: HABLAR SOBRE PROCESO CREATIVO.
Cómo saber qué doble de test aplicar
El truco para saber cuál usar en cada momento es igual que cuando intentamos decidir qué patrón de diseño aplicar… hay que pensar en “la intención”.
Sobre ese andamio de intención podemos plantearnos qué doble de test sería el más ideal. también, pensar en el problema desde la intención nos puede arrojar luz sobre algún mal olor o implementación del código del que no hemos sido conscientes al principio de nuestro proceso creativo.
Tipos de dobles de test
Empecemos por categorizar los dobles de test:
Según Martin Fowler, los tests se categorizan en 5 tipos:
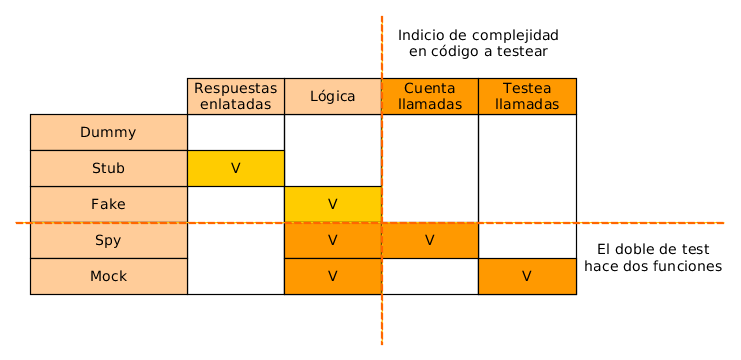
Dummy: Los objetos dummy se pasan pero se sabe que no van a ser usados en el proceso que se va a testear. Simplemente se pasa un objeto de un tipo sin datos ni lógica para cumplir una inyección de dependencia, por ejemplo.
Fake: Los objetos fake tienen cierta lógica que simula el correcto funcionamiento de el objeto complejo que sustituye, pero no se puede usar para el entorno de producción (un InMemoryRepository sería un ejemplo perfecto)
Stub: Proporciona respuestas predefinidas para ciertas llamadas a funciones que necesita el test, pero no implementa lógica. (un objeto que nos de siempre una hora o fecha concreta sería un ejemplo)
Spy: Un spy es un stub pero se guarda si hemos llamado a ciertas funciones y podemos posteriormente interrogarlo sobre ello. Un ejemplo sería guardar la cantidad de mensajes que hemos intentado enviar en un proceso.
Mock: Un mock es algo más complejo que un spy. Ya que tiene sus mismas capacidades pero funcionan de forma diferente. Un mock tiene una serie de llamadas a funcinones y sus respuestas predefinidas, formando una “especificación”. Cuando se usa en un test y no se cumple esa especificación, el test fallará, tanto si se llama a una función no esperada como si no se llaman a todas las funciones predefinidas en la especificación.
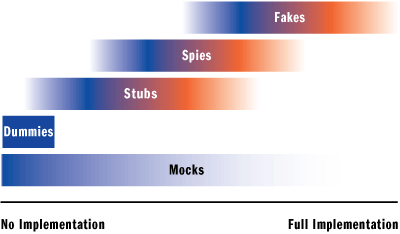
Por complejidad de implementación el orden debería ser:
- Dummy
- Stub
- Spy
- Mock
- Fake
Pero vamos a darle otra perspectiva… vamos a categorizarlos por utilidad/necesidad. Un tipo de doble de test tiene un fin, y si se usa el doble de test reflexionando su utilidad, podemos darnos cuenta de un fallo de implementación de nuestro código que de otra forma podría ser tarde para resolverlo.
Categorizando utilidad/necesidad podemos describirlo así:
- Dummy
- Stub
- Fake
- Spy
- Mock
En esta lista, vemos que el Fake escala posiciones en detrimento del Spy y el Mock. Y es por un motivo concreto. Aunque en el Fake, su complejidad de implementación puede ser alta al intentar suplir una fucionalidad casi completa, por intención es un doble de test imprescindible en los repositorios InMemory.
Si nos fijamos en las capacidades de cada doble de test, intuímos que el Spy y el Mock, aunque devuelven valores como un Stub, intentan testear que se cumple un comportamiento, por ejemplo, que se llaman a unas funciones concretas una cantidad de veces o en un orden concreto.
En este gráfico podemos hacernos una idea de la perspectiva que intento ilustrar:
Qué te puedes encontrar ahí fuera…

Suelo ver que se usan los Fake, Stub y Mock dejando de lado al resto, ya que el Mock puede suplir a Spy en sus funciones, y el Dummy es poco común que lo necesitemos.
Qué debería encontrarse si nos parásemos a reflexionar…
Insisto en este tema. Los dobles de test tienen sus particularidades por algo. Hay que escoger el doble de test adecuado, con la funcionalidad justa y necesaria para cada ocasión. Total… si no fuera así, podríamos usar el mock para casi todo… pero en este caso nos perderíamos parte del momento crítico en nuestro proceso creativo que nos indica que algo no huele bien. Y si posteriormente se ha de cambiar, estaríamos ciegos también en ese caso.
Además, montar un Mock consume más tiempo y recursos de máquina y programador, y un Spy, aunque es más rápido, requiere también que le programemos respuestas a medida y luego interroguemos sus llamadas… eso es incremento de complejidad en el test y el objeto suele ser poco reutilizable fuera del ámbito del test para el que lo diseñamos, cosa que no pasa con el Dummy, Fake y Stub (este último depende de la situación).
De la misma manera, los Mock y los Spy hacen varias cosas, con lo que es un indicador de que estamos intentando contener algo grande que se nos escapa al objetivo del mismo test (con una excepción que se comenta más abajo).
Por ejemplo, a medida que vamos usando un doble de test más complejo, indica que nuestro código está mal o poco segmentado. Cuando usamos un Spy o un Mock, hay que evaluar nuestra intención:
- Si nuestro pensamiento nos dice… ”no podemos testear esta parte de código y buscamos testear el comportamiento controlando sus llamadas y sus respuestas”. Aquí hay algo que no funciona… y debemos resolver.
- Si por el contrario nos dice… “ lo que sustituyo es algo de infraestructura, pero necesito saber si se ha usado en la clase cierta llamada para verificar que el objeto hace lo que debería”… entonces podemos estar tranquilos.
Espero que este pequeño artículo os haya servido de ayuda a la hora de identificar qué tipo de test aplicar y las ventajas e inconvenientes de cada uno.
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email